简单介绍DeepFaceLab(DeepFake)的使用以及容易被忽略的事项

DeepFaceLab相关文章
一:《简单介绍DeepFaceLab(DeepFake)的使用以及容易被忽略的事项》
二:《继续聊聊DeepFaceLab(DeepFake)不断演进的2.0版本》
三:《如何翻译DeepFaceLab(DeepFake)的交互式合成器》
四:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(一)》
五:《想要提高DeepFaceLab(DeepFake)质量的注意事项和技巧(二)》
六:《友情提示DeepFaceLab(DeepFake)目前与RTX3080和3090的兼容问题》
七:《高效使用DeepFaceLab(DeepFake)提高速度和质量的一些方法》
八:《支持DX12的DeepFaceLab(DeepFake)新版本除了CUDA也可以用A卡啦》
九:《简单尝试DeepFaceLab(DeepFake)的新AMP模型》
十:《非常规的DeepFaceLab(DeepFake)小花招和注意事项》
文章目录
(一)关于DeepFaceLab
DeepFaceLab 是一个应用机器学习进行视频中人物换脸的工具
曾经在Reddit上一个很火的开源项目Deepfake。
随着大家的惊呼,神奇女侠的换脸视频出现,然后这个项目就被各大网站给禁了。
沉寂了一段时间后来国内朱茵换杨幂,加上徐锦江的海王雷神视频一出,
国内社会新闻进行了报道,个人感觉一下子在国内就火了。
除了DeepFaceLab,相关的项目还有FaceSwap,OpenFaceSwap等其它作者的工具软件。
(二)必要的信息
DeepFaceLab网站:https://deepfakes.club
实际指向github的:https://github.com/iperov/DeepFaceLab (作者iperov)
git地址:https://github.com/iperov/DeepFaceLab.git
中文网站:https://deepfakescn.com (已获得作者授权)新的内容在这。
过期的中文网站:https://deepfakes.com.cn/
(三)下载安装
具体的下载安装各方面的文章请参考上面的网站,下面主要介绍几个问题。
预编译好的Windows版本
原作者提供了预编译好的Windows版本,并且告诉我们依赖库都有了,只需要自己去安装nVidia的驱动。
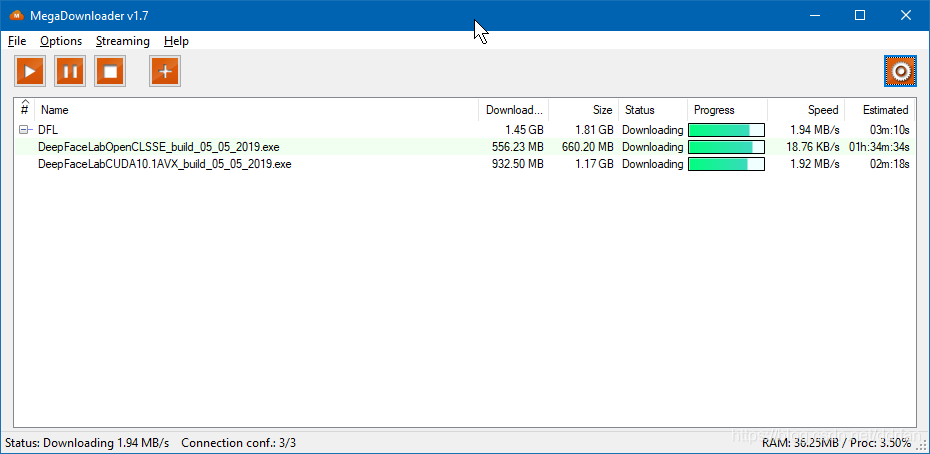
并且还贴心的准备了使用GPU和CPU版本, 可以从MEGA下载:
https://mega.nz/#F!b9MzCK4B!zEAG9txu7uaRUjXz9PtBqg
编译的版本大概分这几类:
- DeepFaceLabCUDA9.2SSE – NVIDIA显卡最高支持到GTX1080和任何64位CPU
- DeepFaceLabCUDA10.1AVX – NVIDIA显卡最高支持到RTX和支持AVX指令集的CPU
- DeepFaceLabOpenCLSSE – AMD/IntelHD显卡和任何64位CPU
重点是:
- 不需要微软Visual Studio 2015,老中文网写的,毕竟怎么说也只需要SDK不可能需要IDE啊。
- Mega地址可以用MegaDownloader v1.7下载,不需要翻墙或者找百度盘上的旧版本。
- 真的得用GPU不要勉强用CPU,我们难以接受机器不眠不休处理一个月才有结果吧?
MegaDownloader下载
拉取git最新版本源码
因为是Python程序,所以下载了预编译好的Windows版本后,除了检查作者是否有更新。
还可以直接git拉取作者的最新版本程序到:
%你安装的DeepFaceLab目录%\_internal\DeepFaceLab\
目录结构
下载了预编译的Windows版本后,解压目录结构如下:
除了两个目录,就是一堆批处理(可以跟随中文网站的步骤做,但还是建议自己仔细阅读批处理文件名,以及最后的pdf手册)。
%你安装的DeepFaceLab目录%
_internal #内部目录,源代码,库,软件。
workspace #工作目录,放原始视频和目标视频
1) clear workspace.bat
2) extract images from video data_src.bat
3.1) cut video (drop video on me).bat
3.2) extract images from video data_dst FULL FPS.bat
3.other) denoise extracted data_dst.bat
4) data_src extract faces MANUAL.bat
4) data_src extract faces MT all GPU debug.bat
4) data_src extract faces MT all GPU.bat
4) data_src extract faces MT best GPU.bat
4) data_src extract faces S3FD all GPU debug.bat
4) data_src extract faces S3FD all GPU.bat
4) data_src extract faces S3FD best GPU.bat
4.1) data_src check result.bat
4.2.1) data_src sort by blur.bat
4.2.2) data_src sort by similar histogram.bat
4.2.4) data_src sort by dissimilar face.bat
4.2.4) data_src sort by dissimilar histogram.bat
4.2.5) data_src sort by face pitch.bat
4.2.5) data_src sort by face yaw.bat
4.2.6) data_src sort by final.bat
4.2.other) data_src sort by black.bat
4.2.other) data_src sort by brightness.bat
4.2.other) data_src sort by hue.bat
4.2.other) data_src sort by one face in image.bat
4.2.other) data_src sort by original filename.bat
4.2.other) data_src util add landmarks debug images.bat
4.2.other) data_src util recover original filename.bat
5) data_dst extract faces MANUAL RE-EXTRACT DELETED RESULTS DEBUG.bat
5) data_dst extract faces MANUAL.bat
5) data_dst extract faces MT all GPU .bat
5) data_dst extract faces MT all GPU + manual fix.bat
5) data_dst extract faces MT best GPU.bat
5) data_dst extract faces S3FD all GPU + manual fix.bat
5) data_dst extract faces S3FD all GPU.bat
5) data_dst extract faces S3FD best GPU + manual fix.bat
5) data_dst extract faces S3FD best GPU.bat
5.1) data_dst check results debug.bat
5.1) data_dst check results.bat
5.2) data_dst sort by similar histogram.bat
5.3) data_dst sort by blur.bat
5.3) data_dst sort by dissimilar histogram.bat
5.3) data_dst sort by face pitch.bat
5.3) data_dst sort by face yaw.bat
5.3.other) data_dst sort by final.bat
5.3.other) data_dst sort by original filename.bat
5.3.other) data_dst util recover original filename.bat
5.4) data_dst mask editor.bat
6) train DF.bat
6) train H128.bat
6) train H64.bat
6) train LIAEF128.bat
6) train SAE.bat
7) convert DF debug.bat
7) convert DF.bat
7) convert H128 debug.bat
7) convert H128.bat
7) convert H64 debug.bat
7) convert H64.bat
7) convert LIAEF128 debug.bat
7) convert LIAEF128.bat
7) convert SAE debug.bat
7) convert SAE.bat
8) converted to avi.bat
8) converted to mov(lossless+alpha).bat
8) converted to mp4(lossless+alpha).bat
8) converted to mp4.bat
9) util convert aligned PNG to JPG (drop folder on me).bat
changelog_en.txt
manual_en.txt
manual_en_google_translated.pdf
manual_ru.pdf
(四)使用软件
放置素材文件
文件就这么放,名字也是固定的。
%你安装的DeepFaceLab目录%\workspace\data_src.mp4 #源视频,用它的脸。
%你安装的DeepFaceLab目录%\workspace\data_dst.mp4 #目标视频,替换到它身上。
预处理视频生成帧图片
2) extract images from video data_src.bat #从源视频生成静态帧图片,可以选帧率(图片数)。
3.2) extract images from video data_dst FULL FPS.bat #从目标视频生成全部帧图片,可以先用3.1截取小段。
生成后的帧图片放置在如下目录:
%你安装的DeepFaceLab目录%\workspace\data_dst\
%你安装的DeepFaceLab目录%\workspace\data_src\
生成脸部数据
4) data_src extract faces S3FD all GPU.bat #从源静态帧图片,生成源脸部。
5) data_dst extract faces S3FD all GPU.bat #从目标静态帧图片,生成目标脸部。
生成后的脸部图片放置在如下目录:
%你安装的DeepFaceLab目录%\workspace\data_dst\aligned\
%你安装的DeepFaceLab目录%\workspace\data_src\aligned\
别急着下一步,这里需要对图片进行人工筛选。
去掉模糊的源脸部,去掉被遮挡的源脸部,等等。具体可参考英文文档或中文网站。
作者写道:
99.995% 的成功或失败率都是因为糟糕的目标/源的脸部数据
所以你99.995%的时间都应该用在保证你的脸部数据是精心的准备好的。
你不能把素材一股脑全扔进去,否者结果保证令你失望,进去的是垃圾,出来的也是垃圾。
开始训练吧
当你准备好的素材,去掉了糟糕或者识别失败的脸部,就可以训练了。
6) train SAE.bat #不同的训练方式请参考文档,或者中文网站。
训练后生成的模型数据放在这个目录:
%你安装的DeepFaceLab目录%\workspace\model\
训练时间可能会很长,训练的参数得自己去理解。。。
Running trainer.
Loading model...
Press enter in 2 seconds to override model settings.Using plaidml.keras.backend backend.
INFO:plaidml:Opening device "%这里应该显示找到的你的显卡或CPU%"
Loading: 100%|######################################################################| 323/323 [00:02<00:00, 147.40it/s]
Loading: 100%|######################################################################| 302/302 [00:02<00:00, 120.54it/s]
===== Model summary =====
== Model name: SAE
==
== Current iteration: 63060
==
== Model options:
== |== batch_size : 4
== |== sort_by_yaw : False
== |== random_flip : False
== |== resolution : 128
== |== face_type : f
== |== learn_mask : True
== |== optimizer_mode : 1
== |== archi : df
== |== ae_dims : 512
== |== e_ch_dims : 42
== |== d_ch_dims : 21
== |== multiscale_decoder : False
== |== ca_weights : True
== |== pixel_loss : True
== |== face_style_power : 0.0
== |== bg_style_power : 0.0
== |== remove_gray_border : False
== Running on:
== |== [0 : %这里应该显示找到的你的显卡和使用的SDK%]
=========================
Starting. Press "Enter" to stop training and save model.
[11:35:27][#063063][1.304s][0.0123][0.0056] #时钟,迭代次数,每次用时,偏离度
同时会显示一个训练的预览窗口,可以看到图像的偏离度越来越低。
可以在上面按回车键停止训练。
(图片已经删除)
合成训练结果(到图片)
选择怎么训练的,就选择对应的合成方式。
7) convert SAE.bat #合成的参数得自己好好理解,多尝试组合。
合成的目标帧图片放在这个目录:
%你安装的DeepFaceLab目录%\workspace\data_dst\merged\
生成视频
8) converted to mp4.bat #合成的参数得自己好好理解,多尝试组合。
生成好的目标视频在这里:
%你安装的DeepFaceLab目录%\workspace\result.mp4
哈哈,结果不满意吧:)
请仔细阅读上面一大段黄色背景的文字,
请仔细阅读文档,重新准好你的素材吧:)
(五)不同的模型与参数(补充)
训练模型
- H64 (2GB +):分辨率为64的半脸模型,适合2-3GB显存,当然质量也较低。
- H128 (3GB +):分辨率为128的半脸模型,适合3-4GB显存,半脸模型某些光线条件下会很糟糕。
- DF (5GB +):分辨率为128的全脸模型,适合5GB以上显存,有条件就可以用这个。
- LIAEF128 (5GB +):和DF一样,只从源到目标变形,有些时候会很怪,那么还是选DF吧。
- SAE (512MB +):最新最好最弹性的模型,包括其它所有模型,512MB-24GB显存都可用,参数多。
训练参数
H64,H128 模型的参数:
Use lightweight autoencoder? (Y / n,:? Help skip: n):
选择一个简版的模型,如果你的显存小于4GB,这个选项就很必要。
H64, H128, DF, LIAEF128 模型的参数:
Use pixel loss? (Y / n,:? Help skip: n / default):
更容易提升细节质量和去除图像颤动,请在训练至少20000次以后再打开这个选项(有模型崩溃风险)。
SAE 模型的参数:
Resolution (64-256:? Help skip: 128):分辨率从64到256,16的倍数,愈大越清晰,训练也需要越长。
Half or Full face? (H / f,:? Help skip: f):半脸还是全脸。
Learn mask? (Y / n,:? Help skip: y):学习的遮罩,呃,懒得翻译了,用它就对了。
Optimizer mode? (1,2,3:? Help skip:% d):N卡的神经网络优化模式,越大需要内存越多,也会更慢。
AE architecture (df, liae, vg:? Help skip: df):神经网络结构,缺省df。
AutoEncoder dims (128-1024:? Help skip:% d):网络维度,越多越好(但是内存得够啊)。
Encoder dims per channel (21-85:? Help skip:% d):也是越多越好(但是内存得够啊)根据显卡配置吧。
Decoder dims per channel (11-85:? Help skip:% d):同上(decoder的维度)。
Remove gray border? (Y / n,:? Help skip: n):去掉灰边,我记得已经没有这个选项了啊???
Use CA weights? (Y / n,:? Help skip:% s):是否使用卷积感知权重,提高模型精度,初始化要点时间。
Use multiscale decoder? (Y / n,:? Help skip: n):是否使用多路转换decoder,获得更高精度。
Use pixel loss? (Y / n,:? Help skip: n / default):更容易提升细节质量和去除图像颤动,请在训练难以提升质量以后再打开这个选项(有模型崩溃风险)。
Face style power (0.0 … 100.0:? Help skip:% 1f.):脸部特征影响值,加速转换学习的脸部特征(有模型崩溃风险)。搞不懂先别开哦。
Background style power (0.0 … 100.0:? Help skip:% 1f.):背景特征影响值,加速转换学习的脸部特征(有模型崩溃风险)。搞不懂先别开哦。
Apply random color transfer to src faceset? (Y / n,:? Help skip:% s):源脸随机颜色转换,比上面两个更加精确。需要学习更多的源脸。
Pretrain the model? (Y / n,:? Help skip: n):预先训练模型(已经包含了的许多不同的人脸模型)
转换参数
通常不变的参数:
Choose mode: (4) seamless
Seamless hist match? : y
Hist match threshold: 255
Mask mode: (1) learned,
下面的参数就值得调整了:
Choose erode mask modifier [-200…200] (skip:0) :决定缩小多少目标遮罩(值<0则是扩展遮罩)
Choose blur mask modifier [-200…200] (skip:0) :决定平滑目标遮罩的值。
Choose output face scale modifier [-50…50] (skip:0) : 源脸放大还是缩小(先试试0,再根据实际情况)
Apply color transfer to predicted face? Choose mode ( rct/lct skip:None ) : 两种都试试吧。
Degrade color power of final image [0…100] (skip:0) : 降低源脸的色彩值,根据实际情况设置。
2.本站所有内容均由互联网收集整理,仅供大家参考、学习,禁止商用。
3.本站所有内容版权归原著所有,如有侵权请及时联系我们做删除处理。
请扫描下方二维码关注微信公众号或直接微信搜索“小青苔基地”关注

小青苔基地 » 简单介绍DeepFaceLab(DeepFake)的使用以及容易被忽略的事项